kenkeep
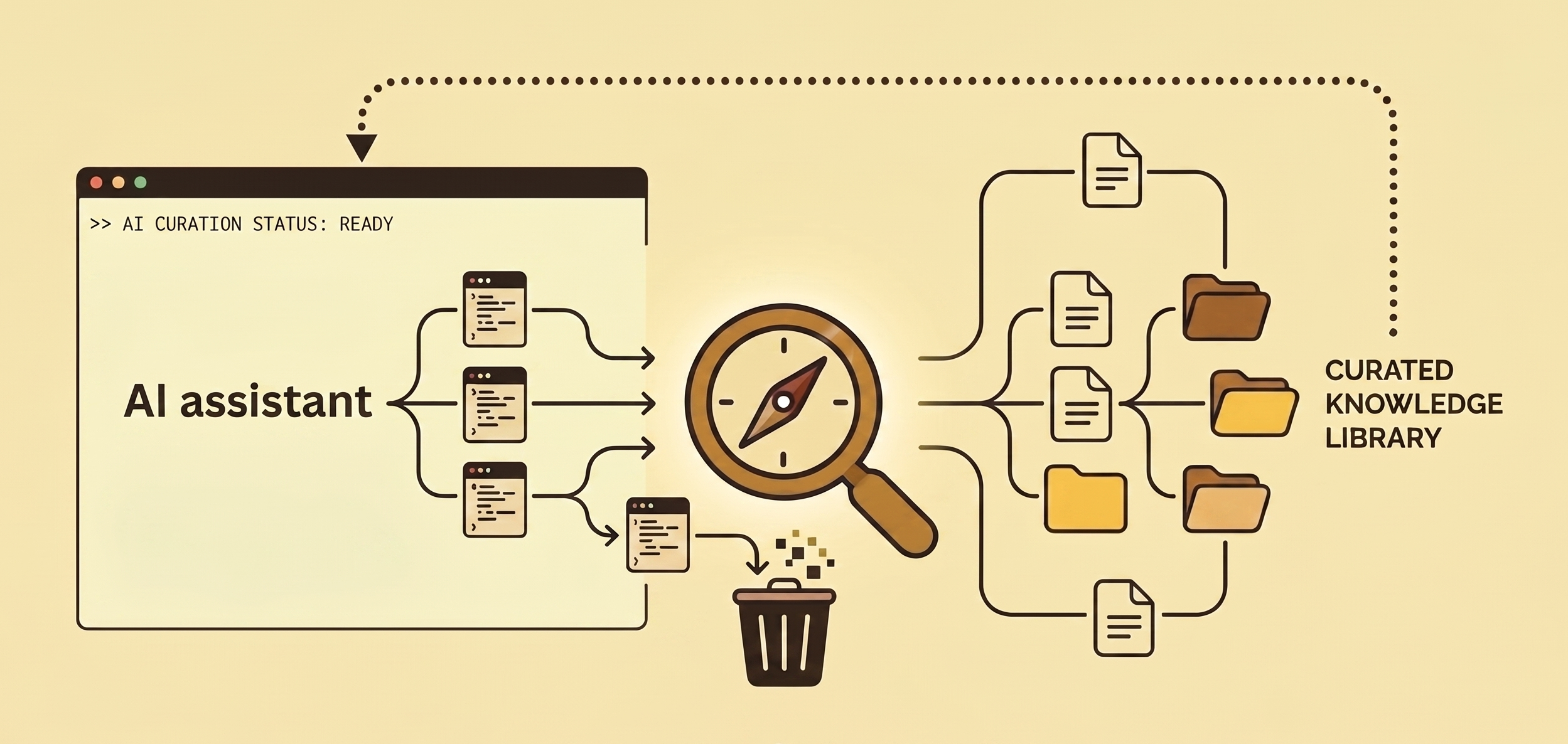
Coding assistants forget about everything in past sessions. Kenkeep creates a system that salvages the gold nuggets in your past conversations, and discards the rest. This way, the assistant can use that important detail you shared two weeks ago, without you even worrying about it.
Kenkeep is a team-shared, git-native knowledge base for AI coding assistants.
Your AI conversations produce a steady stream of project-specific knowledge (conventions, gotchas, named modules, decision rationale), and most of it evaporates when the session ends. This tool captures it, asks a human to curate it, commits it to the repo, and injects it back into every future session.
Why kenkeep?
How is kenkeep different from solutions like claude-mem or MemPalace?
Built up and shared across your team
The knowledge base grows in your repo as plain markdown, one node per fact, accumulated from real coding sessions. It travels with the project through git pull, so every teammate works from the same conventions instead of rediscovering them on their own laptop.
Reviewed and versioned like code
Nothing reaches the knowledge base without a human approving it. Every addition or change is an ordinary git diff you review in a commit or PR, with the full history there to inspect, blame, or revert like any other code.
Quick start
npx kenkeep init --harnesses claude
npx kenkeep doctor
Swap claude for codex, cursor, opencode, or copilot to match your harness; pass a comma-separated list to install several at once.
Then code normally. When you want to turn captured material into knowledge nodes, run /kk-curate inside your harness session (also /kk-add, /kk-bootstrap). The skills are context-aware and walk you through conflict resolution. New nodes appear in nodes/; review with git diff and commit the ones you want to keep.
Seed from existing docs
If your repo already has READMEs, ADRs, or module docs, seed the knowledge base from them. Inside a harness session:
/kk-bootstrapThe scan walks the repo root, filtered by .kkignore (generated by init, uses gitignore-style syntax). Edit .kkignore to exclude directories you don't want scanned. Review the resulting nodes under nodes/ with git diff and commit the ones you want to keep.
Add knowledge manually
At any time, during your LLM conversations you can use /kk-add to ensure the LLM remembers your message. Just casually mention it, and you are done.
Example:
No, you got that wrong.
This project aims to maximize code
re-use, instead of duplication. Adapt
and extend the abstractions to fit
this use case. Also, /kk-add this.How it works
kenkeep runs a loop around your AI sessions. Capture and injection happen on their own. You trigger curation, and you decide what to keep.
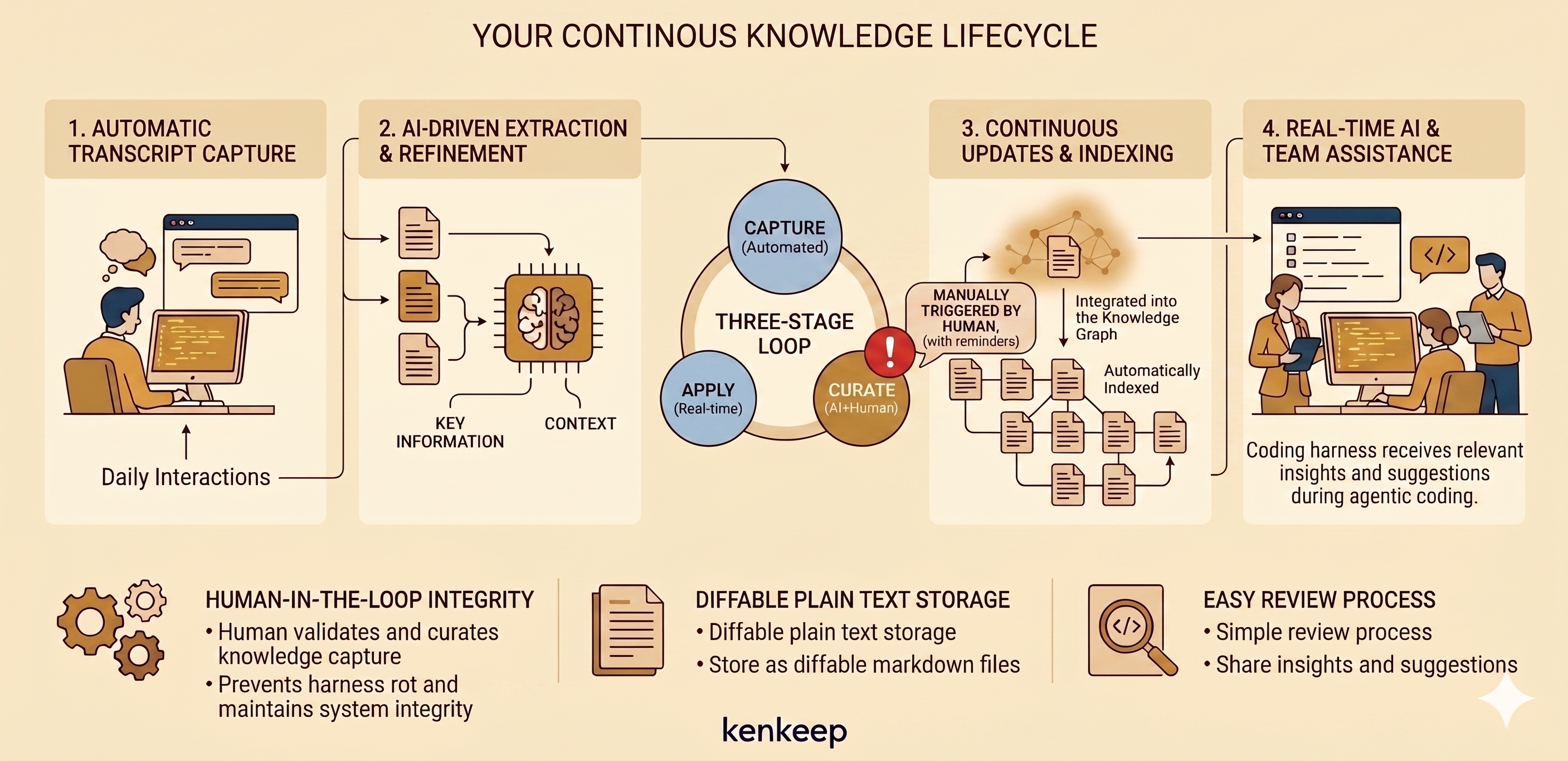
Read next
- How it works - the 3-minute version.
- Installation - prerequisites and first-time setup.
- Daily use - the loop you’ll run week to week.
- Knowledge packs - import and publish portable knowledge bases.
- Troubleshooting - when something looks wrong.
Curious how ENTRY.md actually reaches the harness on every session start? See Internals → Hooks. These are the harness’s own hooks (Claude Code’s SessionStart, Stop, etc.) that we register into, not an extension API exposed by kenkeep.
Contributors: see Internals.