This is a re-post of the article I wrote for the Lullabot blog.
The Schemata module is our best approach so far in order to provide schemas for our API resources. Unfortunately, this solution is often not good enough. That is because the serialization component in Drupal is so flexible that we can’t anticipate the final form our API responses will take, meaning the schema that our consumers depend on might be inaccurate. How can we improve this situation? This article is part of the Decoupled hard problems series. In past articles, we talked about request aggregation solutions for performance reasons, and how to leverage image styles in decoupled architectures.
TL;DR
- Schemas are key for an API's self-generated documentation
- Schemas are key for the maintainability of the consumer’s data model.
- Schemas are generated from Typed Data definitions using the Schemata module. They are expressed in the JSON Schema format.
- Schemas are statically generated but normalizers are determined at runtime.
Why Do We Need Schemas?
A database schema is a description of the data a particular table can hold. Similarly, an API resource schema is a description of the data a particular resource can hold. In other words, a schema describes the shape of a resource and the datatype of each particular property.
Consumers of data need schemas in order to set their expectations. For instance, the schema tells the consumer that the body property is a JSON object that contains a value that is a string. A schema also tells us that the mail property in the user resource is a string in the e-mail format. This knowledge empowers consumers to add client-side form validation for the mail property. In general, a schema will help consumers to have a prior understanding of the data they will be fetching from the API, and what data objects they can write to the API.
We are using the resource schemas in the Docson and Open API to generate automatic documentation. When we enable JSON API and Open API you get a fully functional and accurately documented HTTP API for your data model. Whenever we make changes to a content type, that will be reflected in the HTTP API and the documentation automatically. All thanks to the schemas.
A consumer could fetch the schemas for all the resources it needs at compile time or fetch them once and cache them for a long time. With that information, the consumer can generate its models automatically without developer intervention. That means that with a single implementation once, all of our consumers’ models are done forever. Probably, there is a library for our consumer’s framework that does this already.
More interestingly, since our schema comes with type information our schemas can be type safe. That is important to many languages like Swift, Java, TypeScript, Flow, Elm, etc. Moreover, if the model in the consumer is auto-generated from the schema (one model per resource) then minor updates to the resource are automatically reflected in the model. We can start to use the new model properties in Angular, iOS, Android, etc.
In summary, having schemas for our resources is a huge improvement for the developer experience. This is because they provide auto-generated documentation of the API and auto-generated models for the consumer application.
How Are We Generating Schemas In Drupal?
One of Drupal 8’s API improvements was the introduction of the Typed Data API. We use this API to declare the data types for a particular content structure. For instance, there is a data type for a Timestamp that extends an Integer. The Entity and Field APIs combine these into more complex structures, like a Node.
JSON API and REST in core can expose entity types as resources out of the box. When these modules expose an entity type they do it based on typed data and field API. Since the process to expose entities is known, we can anticipate schemas for those resources.
In fact, assuming resources are a serialization of field API and typed data is the only thing we can do. The base for JSON API and REST in core is Symfony’s serialization component. This component is broken into normalizers, as explained in my previous series. These normalizers transform Drupal’s inner data structures into other simpler structures. After this transformation, all knowledge of the data type, or structure is lost. This happens because the normalizer classes do not return the new types and new shapes the typed data has been transformed into. This loss of information is where the big problem lies with the current state of schemas.
The Schemata module provides schemas for JSON API and core REST. It does it by serializing the entity and typed data. It is only able to do this because it knows about the implementation details of these two modules. It knows that the nid property is an integer and it has to be nested under data.attributes in JSON API, but not for core REST. If we were to support another format in Schemata we would need to add an ad-hoc implementation for it.
The big problem is that schemas are static information. That means that they can’t change during the execution of the program. However, the serialization process (which transforms the Drupal entities into JSON objects) is a runtime operation. It is possible to write a normalizer that turns the number four into 4 or "four" depending if the date of execution ends in an even minute or not. Even though this example is bizarre, it shows that determining the schema upfront without other considerations can lead to errors. Unfortunately, we can’t assume anything about the data after its serialized.
We can either make normalization less flexible—forcing data types to stay true to the pre-generated schemas—or we can allow the schemas to change during runtime. The second option clearly defeats the purpose of setting expectations, because it would allow a resource to potentially differ from the original data type specified by the schema.
The GraphQL community is opinionated on this and drives the web service from their schema. Thus, they ensure that the web service and schema are always in sync.
How Do We Go Forward From Here
Happily, we are already trying to come up with a better way to normalize our data and infer the schema transformations along the way. Nevertheless, whenever a normalizer is injected by a third party contrib module or because of improved normalizations with backward compatibility the Schemata module cannot anticipate it. Schemata will potentially provide the wrong schema in those scenarios. If we are to base the consumer models on our schemas, then they need to be reliable. At the moment they are reliable in JSON API, but only at the cost of losing flexibility with third-party normalizers.
One of the attempts to support data transformations and the impact they have on the schemas are Field Enhancers in JSON API Extras. They represent simple transformations via plugins. Each plugin defines how the data is transformed, and how the schema is affected. This happens in both directions, when the data goes out and when the consumers write back to the API and the transformation needs to be reversed. Whenever we need a custom transformation for a field, we can write a field enhancer instead of a normalizer. That way schemas will remain correct even if the data change implies a change in the schema.
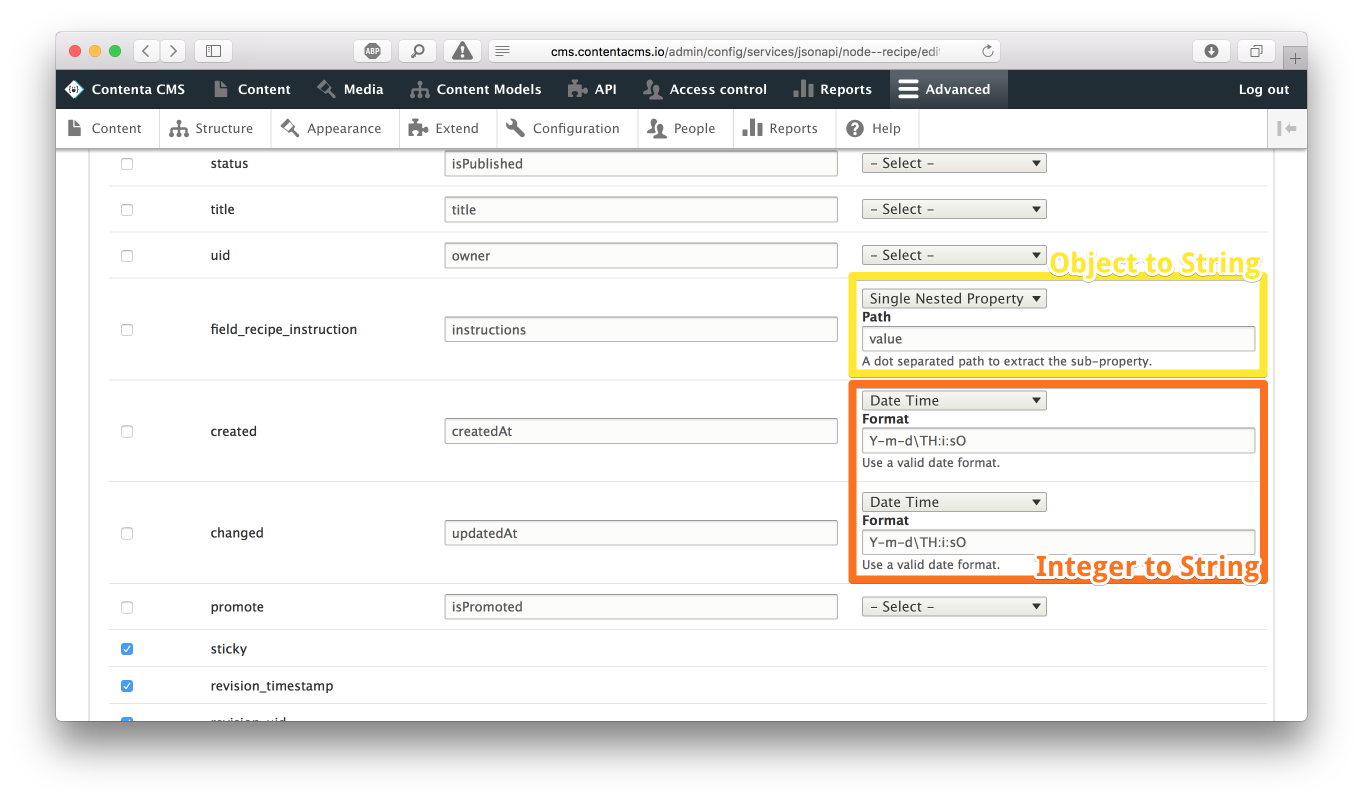
We are very close to being able to validate responses in JSON API against schemas when Schemata is present. It will only happen in development environments (where PHP’s asserts are enabled). Site owners will be able to validate that schemas are correct for their site, with all their custom normalizers. That way, when a site owner builds an API or makes changes they’ll be able to validate the normalized resource against the purported schema. If there is any misalignment, a log message will be recorded.
Ideally, we want the certainty that schemas are correct all the time. While the community agrees on the best solution, we have these intermediate measures to have reasonable certainty that your schemas are in sync with your responses.
Join the discussion in the #contenta Slack channel or come to the next API-First Meeting and show your interest there!
Hero photo by Oliver Thomas Klein on Unsplash.